FP-Growth是一种常被用来进行关联分析,挖掘频繁项的算法。与Aprior算法相比,FP-Growth算法采用前缀树的形式来表征数据,减少了扫描事务数据库的次数,通过递归地生成条件FP-tree来挖掘频繁项。参考资料[1]详细分析了这一过程。事实上,面对大数据量时,FP-Growth算法生成的FP-tree非常大,无法放入内存,挖掘到的频繁项也可能有指数多个。本文将分析如何并行化FP-Growth算法以及Mahout中并行化FP-Growth算法的源码。
1. 并行化FP-Growth
并行化FP-Growth的方法有很多,最早提出使用MapReduce并行化FP-Growth算法的应该是来自Google Beijing Research的Haoyuan Li等。他们提出使用三次MapReduce来并行化FP-Growth,整个过程大致可以分为五个步骤:
Step 1:Sharding
为了均衡整个集群的读写性能,将事务数据库分成若干个数据片段(shard),存储到P个节点中。
Step 2:Parallel Counting
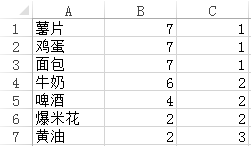
与WordCount类似,通过一次MapReduce来计算每一个项(item)的支持度。具体来说,每一个mapper将从hdfs中取得事务数据库的若干个数据片段(shards),所以mapper的输入是
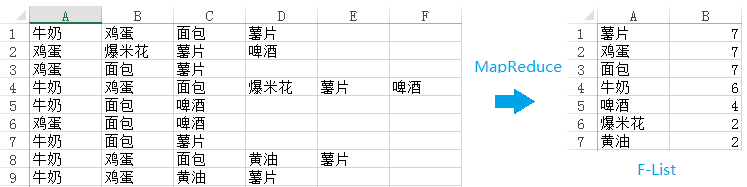
Step 3:Grouping Items
将F-List中的项(item)分为Q个组(group),每一个组都有一个唯一的group-id,我们将所有项以及其所对应的group-id记为G-List。
Step 4:Parallel FP-Growth
这一步骤是并行化FP-Growth的关键,也是整个算法中相对难以理解的部分。这一步骤中将用到一次MapReduce。每一个mapper的输入来自第一步生成的数据片段,所以mapper的输入是
其中,第三列是group-id。假如mapper的输入是{牛奶,鸡蛋,面包,薯片},从最后一项开始扫描,输出
所有group-id相同的数据将被推送到同一个reducer,所以reducer的输入是
Step 5:Aggregating
上一步挖掘到的频繁模式Top K Frequent Patterns已经包含了所有频繁模式,然而上一步的MapReduce是按照groupID来划分数据,因此key=item对应的频繁模式会存在于若干个不同groupID的reduce节点上。为了合并所有key=item的键值对,优化结果展现形式,可利用MapReduce默认对key排序的特点,对挖掘到的频繁模式进行一下处理:依次将Top K Frequent Patterns的每一个item作为key,然后输出包含该key的这一条Top K Frequent Patterns。所以,每一个mapper的输出是
2. Parallel FP-Growth源码分析
Mahout提供了一些机器学习领域经典算法的实现。Mahout0.9之后的版本已经移除了Parallel FP-Growth算法。本文将分析Mahout0.8中Parallel FP-Growth的源码。
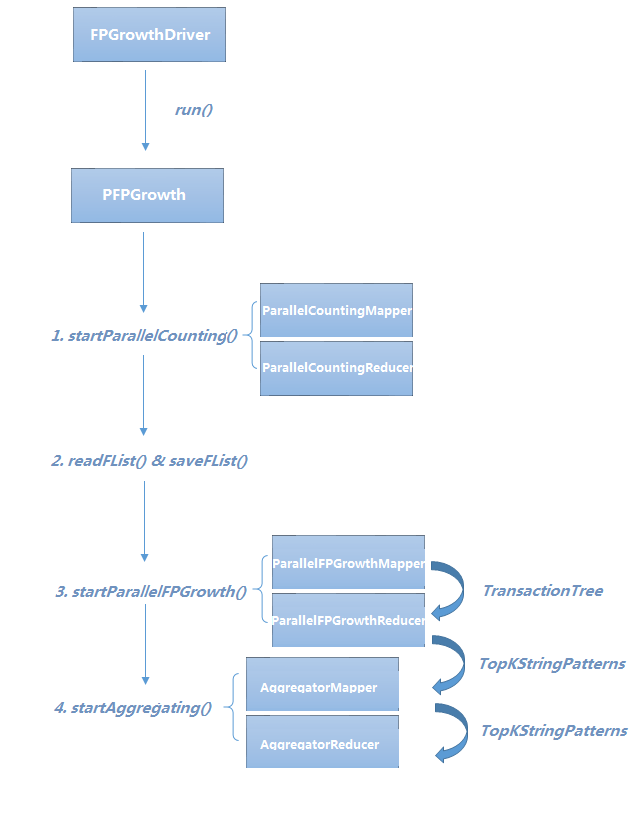
FPGrowthDriver.java
FPGrowthDriver是FPGrowth算法的驱动类,继承自AbstractJob类。运行Hadoop任务一般都是通过命令行中执行bin/hadoop脚本,同时传入一些参数。ToolRunner类中的GenericOptionsParser可获取这些命令行参数。AbstractJob类封装了addInputOption,addOutputOption,addOption,parseArguments等方法,为解析命令行参数提供了帮助。params对象存储了整个算法所需要的参数。FPGrowthDriver根据命令行参数,若顺序执行,则调用该文件内的runFPGrowth方法,若并行化执行,则调用PFPGrowth.java文件中的runPFPGrowth方法。
|
|
PFPGrowth.java
PFPGrowth是并行化FP-Growth算法的驱动类。runPFPGrowth(params)方法内初始化了一个Configuration对象,之后调用runPFPGrowth(params, conf)方法。runPFPGrowth(params, conf)方法包括了并行化FP-Growth算法的五个关键步骤。其中,startParallelCounting(params, conf)对应Step1和Step2,通过类似WordCount的方法统计每一项的支持度,其输出结果将被readFList()和saveList()用于生成FList。之后,将按照用户输入的命令行参数NUM_GROUPS来计算每一个group所含项的个数,并将其存储到params。startParallelFPGrowth(params, conf)对应Step3和Step4。startAggregating(params, conf)对应Step5。
|
|
startParallelCounting方法初始化了一个Job对象。该Job对象将调用ParallelCountingMapper和ParallelCountingReducer来完成支持度的统计。
|
|
ParallelCountingMapper.java
ParallelCountingMapper中map方法的输入分别是字节偏移量offset和事务数据库中的某一行数据input。所有input数据中多次出现的项都被视为出现一次,所以将input数据split之后存储到HashSet中。map方法的输出是
|
|
ParallelCountingReducer.java
ParallelCountingReducer中reduce方法的输入是
|
|
PFPGrowth.java
通过params中的OUTPUT参数可以获取ParallelCountingReducer的输出路径。在readFList这个方法中用到了几个数据结构。Pair实现了Comparable接口和Serializable接口,其数据成员first和second分别用来表示item和item所对应的支持度。PriorityQueue是一个用平衡二叉树实现的小顶堆,如果指定了Comparator,将按照Comparator对PriorityQueue中的元素进行排序,如果未指定Comparator,则将按照元素实现的Comparable接口进行排序。在并行化FP-Growth算法中,初始化PriorityQueue时指定了Comparator,其按照Pair的第一个元素进行排序,如果第一个元素相等,则按照第二个元素进行排序。通过初始化SequenceFileDirIterable来遍历上一次MapReduce输出的结果,每次将Pair添加到PriorityQueue的同时完成排序。最后,逐一将PriorityQueue中的元素取出放入fList。因此,fList是一个按照支持度递减的列表。
|
|
由于已经生成了fList,上一次MapReduce的输出结果已经没有用了,因此,saveFList方法首先删除了这些文件。之后,saveFList方法将flist写入到hdfs上。对于存储在hdfs上的文件,DistributedCache提供了缓存文件的功能,在Slave Node进行计算之前可将hdfs上的文件复制到这些节点上。
|
|
startParallelFPGrowth方法初始化了一个Job对象。该Job对象将调用ParallelFPGrowthMapper和ParallelFPGrowthReducer来实现Step3和Step4。
|
|
ParallelFPGrowthMapper.java
ParallelFPGrowthMapper中的setup方法将在map方法之前被运行。setup方法中调用了readFList方法。注意这里的readFList方法与之前分析的readFList方法参数不一样,所以是两个完全不同的方法。这里的readFList方法通过HadoopUtil.getCachedFiles(conf)来获取缓存文件flist,将其存储到fMap,其中item作为fMap的键,item在flist中的位置序号作为fMap的值,例如flist中的第一个item,其在fMap中将是
|
|
ParallelFPGrowthReducer.java
ParallelFPGrowthReducer的输入是
|
|
TransactionTree.java
在分析fpGrowth.generateTopKFrequentPatterns方法之前,先来分析一下建树过程中使用的addPattern方法。下面的代码列出了TransactionTree的数据成员和addPattern方法。在addPattern方法中,首先从根节点开始与myList中的节点进行比较。childWithAttribute返回temp节点下的孩子节点中是否有和attributeValue名称相同的节点。如果没有,addCountMode置为false,将myList中剩余的节点添加到这棵树中;如果有,则通过addCount方法增加child节点的支持度。这一建树的思路与传统的FP-Growth中建树的思路完全一致。
|
|
FPGrowth.java
generateTopKFrequentPatterns方法的形参有transactionStream,frequencyList,minSupport,k,Collection returnableFeatures,OutputCollector
attributeIdMapping过滤了transactionStream中的非频繁项,并为频繁项分配新id,将其映射成
|
|
AggregatorMapper的输入是
|
|
AggregatorReducer汇总了所有Key相同的item,然后按照支持度递减排序,最终输出Top K个频繁模式。
|
|
3. 讨论
并行化FP-Growth算法解决了大数据量时传统FP-Growth的性能瓶颈。除了并行化FP-Growth算法外,还有许多方法可以优化FP-Growth算法,比如并行化FP-Growth算法时考虑负载均衡,采用极大频繁项集和闭频繁项集表示频繁模式。
极大频繁项集
极大频繁项集是这样的频繁项集,它的直接超集都不是频繁的。极大频繁项集形成了可以导出所有频繁项集的最小项集集合,但是极大频繁项集却不包含它们子集的支持度信息。** 闭频繁项集 ××
如果项集的直接超集都不具有和它相同的支持度并且该项集的支持度大于或等于最小支持度阈值,则该项集是闭频繁项集。闭频繁项集提供了频繁项集的一种最小表示,该表示不丢失支持度信息。
4. 参考资料
[1] 关联分析:FP-Growth算法. Mark Lin. datahunter2014. 2014. [Link]]
[2] PFP: Parallel FP-Growth for Query Recommendation. Haoyuan Li etc. RecSys ‘08 Proceedings of the 2008 ACM conference on Recommender systems. 2008. [PDF]